Release Notes
0.1.9 (2025-07-14)
Fixed
AsyncLavenderDataLoader became faster by using multiprocess.Process and multiprocess.SharedMemory instead of threading.Thread.
Inner join shardsets instead of outer join by default.
Added
Youtube url preview
Youtube urls are now previewed in dataset preview page.
0.1.8 (2025-06-23)
Added
Column statistics
Column statistics are now available in dataset preview page.
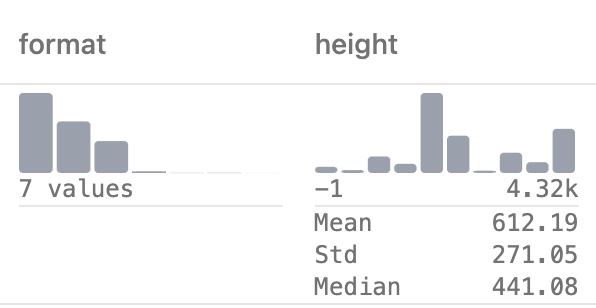
Per-shard column statistics are also provided in shardset detail page.
Go to Shards tab and click on a Statistics button to see the statistics.

Configurable main shardset
You can now manually configure the main shardset for a dataset.

Min-max filter
Added built-in min_max filter.
0.1.6 (2025-06-18)
Fixed
Better media preview
Media preview in dataset preview page now works better.
Now it uses signed URL from the data source, instead of downloading the file to the server.
file:// will be served as static files, from a separated directory.
Faster dataset preview
Shard information is cached in server for faster dataset preview.
0.1.5 (2025-06-16)
Added
Preprocessors, collaters, categorizers, and filters are now auto-refreshed and does not require to restart the server.
Fixed
sync_shardset_location overwrites even if overwrite=False
S3 download fails if path prefix starts with / (e.g. s3://bucket//path)
Next page button in dataset preview page does not work properly
Invalidate reader cache after sync
Hide video preview by default on dataset preview page
0.1.4 (2025-05-27)
Fixed
Image preview in dataset preview page
You can now click on the image to see the image larger in the preview page.
S3 storage
list() method of S3 storage might not work correctly if the target directory is empty.
0.1.3 (2025-05-26)
Added
Run data loader in web UI
You can now test-run data loader in dataset detail page.

Fixed
Log UI start failure
lavender-data server start command let you know when the UI fails to start.
0.1.2 (2025-05-20)
Added
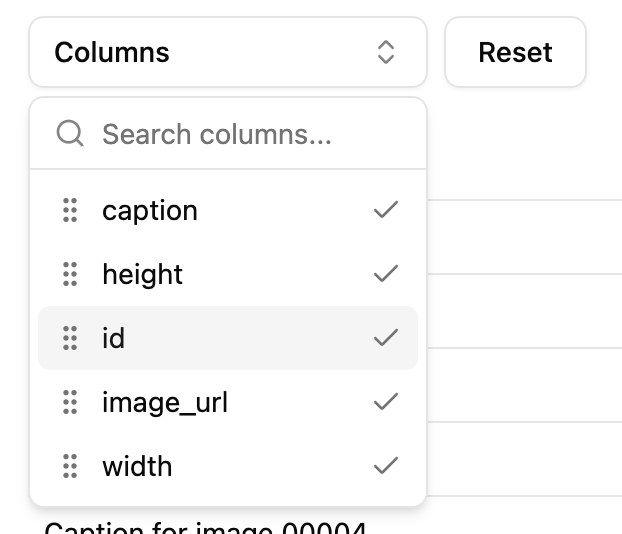
Preview media
Preview media files like images, videos in dataset preview.
Selectable columns
Select columns and sort them as you like.
HTTP Storage
Added HTTP/HTTPS storage support. Fetch files from HTTP/HTTPS URLs.
For example,
https://docs.lavenderdata.com/example-dataset/images/shard.00000.csvshardset_location option for dataset creation
Added shardset_location option so you can create a dataset and the shardset at the same time.
lavender-data client \ datasets create \ --name my_dataset \ --uid-column-name id \ --shardset-location https://docs.lavenderdata.com/example-dataset/images/0.1.1 (2025-05-19)
Added
overwrite, drop_last options for dataset preprocessing
Fixed
Background Preprocessing
Background preprocessing might not preserve the order of samples.
Only one worker is used for background preprocessing.
Server Daemon
Server does not terminate gracefully when lavender-data server stop is called.
Server is not aware of if all background workers are ready or errored.
LavenderDataLoader
LavenderDataLoader unnecessarily calls /version endpoint multiple time.
0.1.0 (2025-05-15)
Added
Categorizer
Please refer here for more details.
Background preprocessing
Please refer here for more details.
0.0.13 (2025-05-12)
Added
Background worker
Heavy tasks like shardset synchronization and sample processing are now running in background workers not to disturb the main process.
Added LAVENDER_DATA_NUM_WORKERS env to control the number of workers for the background worker.
0.0.10 (2025-05-08)
Added
Delete dataset & shardset
Added delete_dataset and delete_shardset APIs as well as in the UI.
0.0.9 (2025-05-02)
Added
Fault handling
Added fault handling features.
skip_on_failureoptionmax_retry_countoption
0.0.8 (2025-04-30)
Added
Daemon commands
Added cli command: start stop restart logs
Those are daemon-related commands.
start starts the server daemon in background. You can stop, restart with stop, restart commands.
lavender-data server start --init> lavender-data is running on 0.0.0.0:8000> UI is running on http://localhost:8000> API key created: la-...You can check the logs from daemon with logs command.
lavender-data server logs -n 100# print last 100 lines of the logs
lavender-data server logs -f# wait for new logs and print themConverters
A Converter is a tool that converts data from a source to a Lavender Data shardset.
import webdataset as wds
url = "https://storage.googleapis.com/webdataset/testdata/publaynet-train-{000000..000009}.tar"pil_dataset = wds.WebDataset(url).decode("pil")
converter = lavender.Converter.get("webdataset")converter.to_shardset( pil_dataset, "dataset_name", location=f"file:///path/to/shardset", uid_column_name="id",)UI breadcrumb
Added breadcrumb
Fixed
Client sdk interface
Before
from lavender_data.client import api as lavender, Iteration
lavender.init(api_url="")
lavender.get_datasets()
for row in Iteration.from_dataset(...).to_torch_data_loader(): ...After
import lavender_data.client as lavender
lavender.init(api_url="")
lavender.api.get_datasets()# orlavender.get_client().get_datasets()# or (in case you need ignore `lavender.init()`)lavender.LavenderDataClient(api_url="").get_datasets()
for row in lavender.LavenderDataLoader(...).torch(): ...0.0.7 (2025-04-21)
Added
Cluster
Added cluster features (LAVENDER_DATA_CLUSTER_* envs, cluster_sync option)
Fixed
Turned env API_URL of UI into runtime so it can be injected when running lavender-data server run
Fixed shards not shuffling bug