Server - Background Preprocess
Start background preprocessing with preprocess_dataset API.
Preprocessed results are saved as a new shardset.
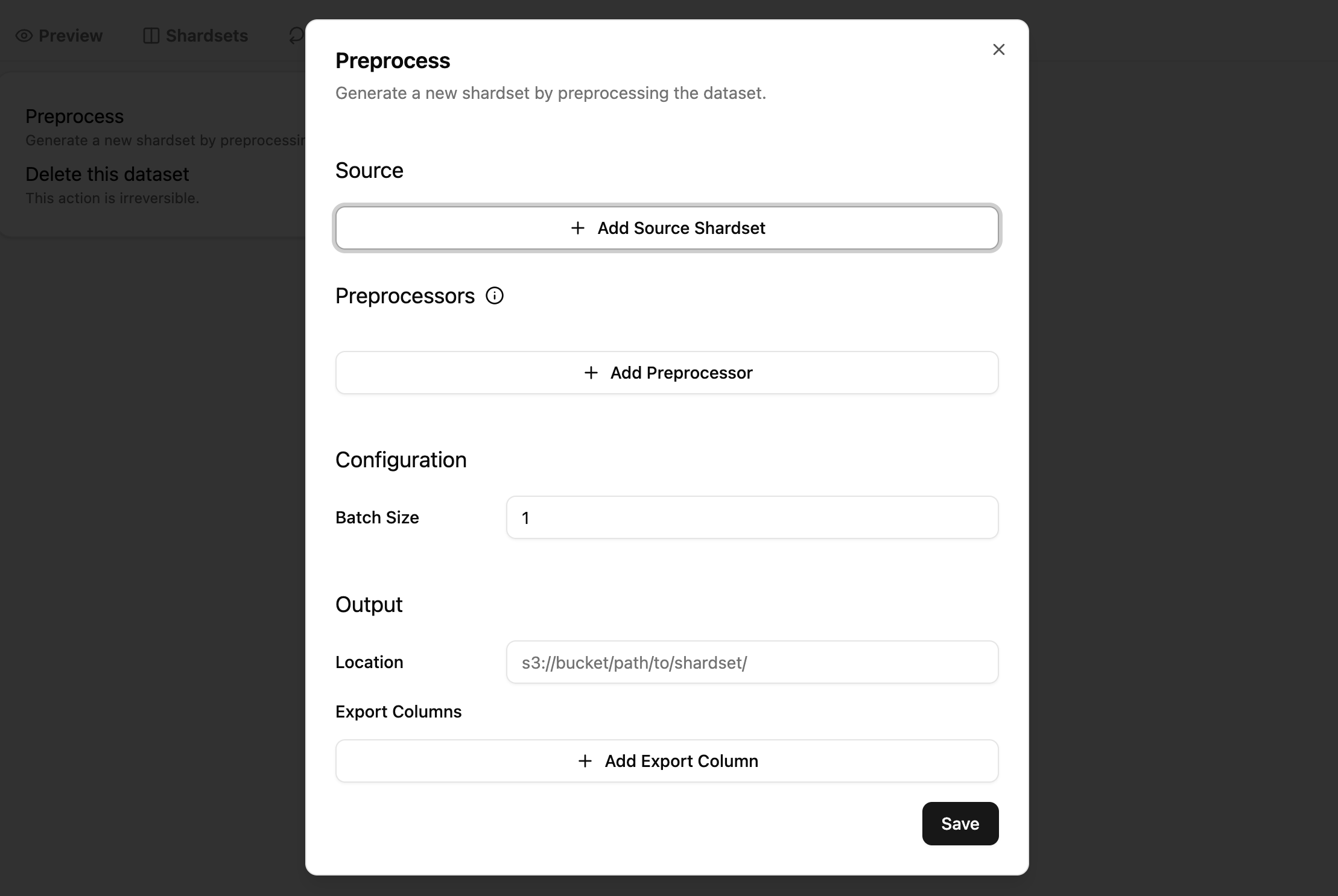
These are the parameters you need to specify:
- Dataset ID
- Source shardset IDs: List of shardsets to preprocess
- Preprocessors: List of preprocessors to apply
- Batch size: Number of samples to process in each batch
- Export columns: List of columns to export
- Destination shardset location: Location to save the preprocessed shardset
Click the “Preprocess” button in the dataset settings page.
The preprocess job will be enqueued and executed in the background.
import lavender_data.client as lavender
lavender.api.preprocess_dataset( # source dataset id dataset_id="dataset-id", # source shardset ids source_shardset_ids=["shardset-id-1", "shardset-id-2"], # preprocessors preprocessors=[ lavender.api.IterationPreprocessor( name="umt5-encode", params={"model_name": "google/umt5-small"}, ) ], batch_size=8, export_columns=["text_embedding"], # destination shardset location shardset_location="file:///path/to/output/shardset",)