Server- Pipeline
Lavender Data’s pipeline consists of several components that process your data from storage to application.
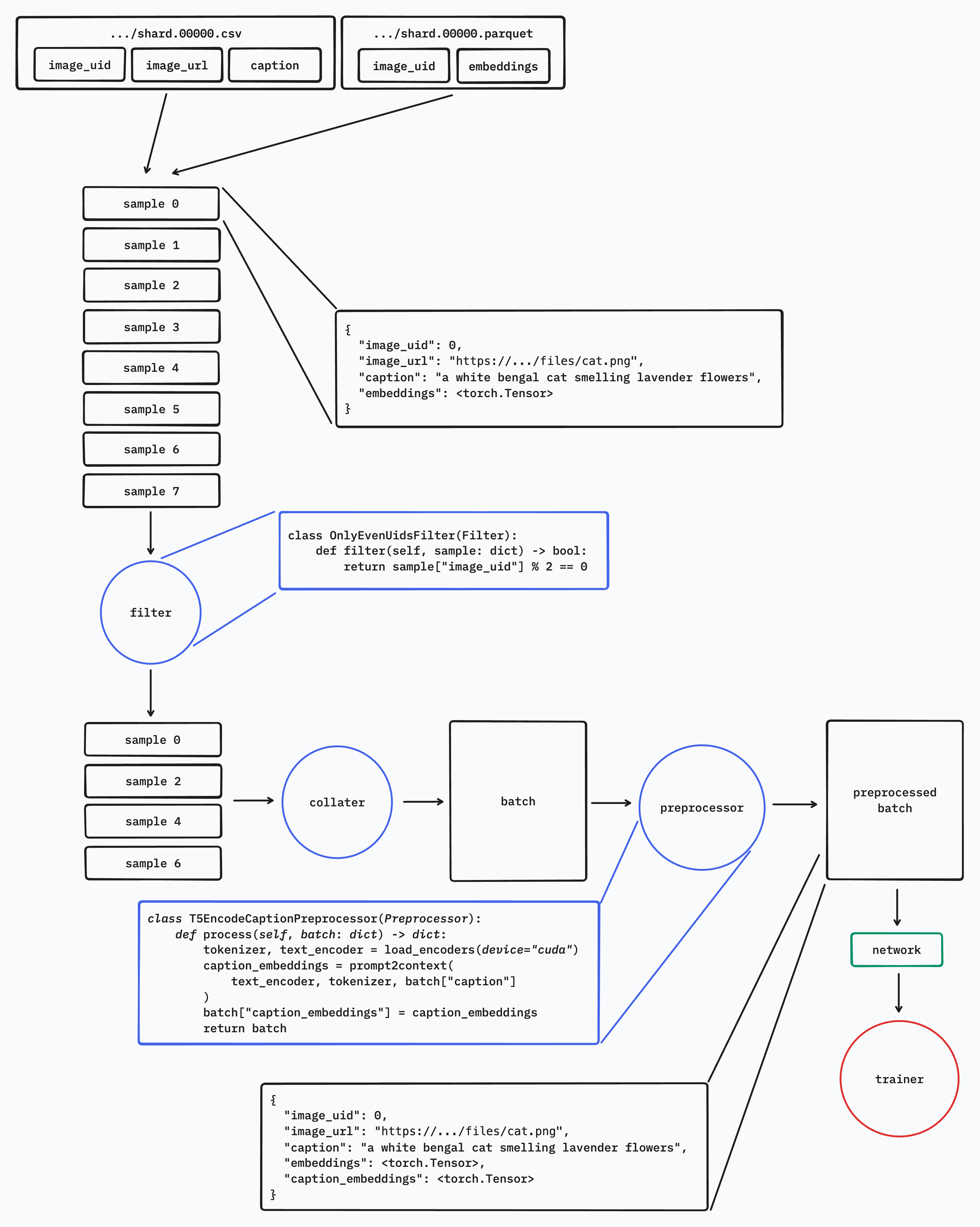
There are four main components:
- Filters: Determine which samples to include/exclude during iteration
- Categorizers: Group samples into batches based on a specific criterion
- Collaters: Control how individual samples are combined into batches
- Preprocessors: Transform batches before they’re returned to your application
Building the Pipeline
Lavender Data allows you to build your own pipeline by defining filters, collaters, and preprocessors.
Module Directory
-
First, create a directory to store your components.
Terminal window mkdir -p ~/.lavender-data/modules -
Then, set the environment variable.
Terminal window export LAVENDER_DATA_MODULES_DIR=~/.lavender-data/modules -
After adding or modifying components, restart the Lavender Data server for the changes to take effect.
Terminal window lavender-data server restart
Filters
Filters determine which samples to include or exclude during iteration. To create a filter:
-
Create a new Python file in your modules directory.
-
Define a class that inherits from
Filterwith a unique name. -
Implement the
filtermethod that returns a boolean.For example, to create a filter that only includes samples with even UIDs:
modules/filter.py from lavender_data.server import Filterclass UidModFilter(Filter, name="uid_mod"):def filter(self, sample: dict, *, mod: int = 2) -> bool:"""Only include samples where uid % mod == 0Args:sample: The individual sample to filtermod: The modulus to use for filtering (default: 2)Returns:bool: True if the sample should be included, False otherwise"""return sample["uid"] % mod == 0
Categorizers
Categorizers group samples into batches based on a specific criterion. To create a categorizer:
-
Create a new Python file in your modules directory.
-
Define a class that inherits from
Categorizerwith a unique name. -
Implement the
categorizemethod that takes a sample and returns a string.For example, to create a categorizer that groups samples by aspect ratio:
modules/categorizer.py from lavender_data.server import Categorizerclass AspectRatioCategorizer(Categorizer, name="aspect_ratio"):"""Categorize samples by aspect ratioArgs:sample: The sample to categorizeReturns:str: The bucket key"""def categorize(self, sample: dict) -> str:return f"{sample['width']}x{sample['height']}"
Collaters
Collaters control how individual samples are combined into batches. To create a collater:
-
Create a new Python file in your modules directory.
-
Define a class that inherits from
Collaterwith a unique name. -
Implement the
collatemethod that takes a list of samples and returns a dictionary.For example, to create a simple Python list collater:
modules/collater.py from lavender_data.server import Collaterclass PyListCollater(Collater, name="pylist"):def collate(self, samples: list[dict]) -> dict:"""Collate samples into a dictionary of listsArgs:samples: List of samples to collateReturns:dict: Dictionary with lists for each field"""result = {}for key in samples[0].keys():result[key] = [sample[key] for sample in samples]return result
Preprocessors
Preprocessors transform batches before they’re returned to your application. To create a preprocessor:
-
Create a new Python file in your modules directory.
-
Define a class that inherits from
Preprocessorwith a unique name. -
Implement the
processmethod that takes a batch and returns a processed batch.For example, to add a new column to each batch:
modules/preprocessor.py from lavender_data.server import Preprocessorclass AppendNewColumn(Preprocessor, name="append_new_column"):def process(self, batch: dict) -> dict:"""Add a new column to the batchArgs:batch: The batch to processReturns:dict: The processed batch with a new column"""batch["new_column"] = []for uid in batch["uid"]:batch["new_column"].append(f"{uid}_processed")return batch