Core Concepts
Dataset Server
You might need to preprocess your data on the training nodes which takes a lot of time and resources.
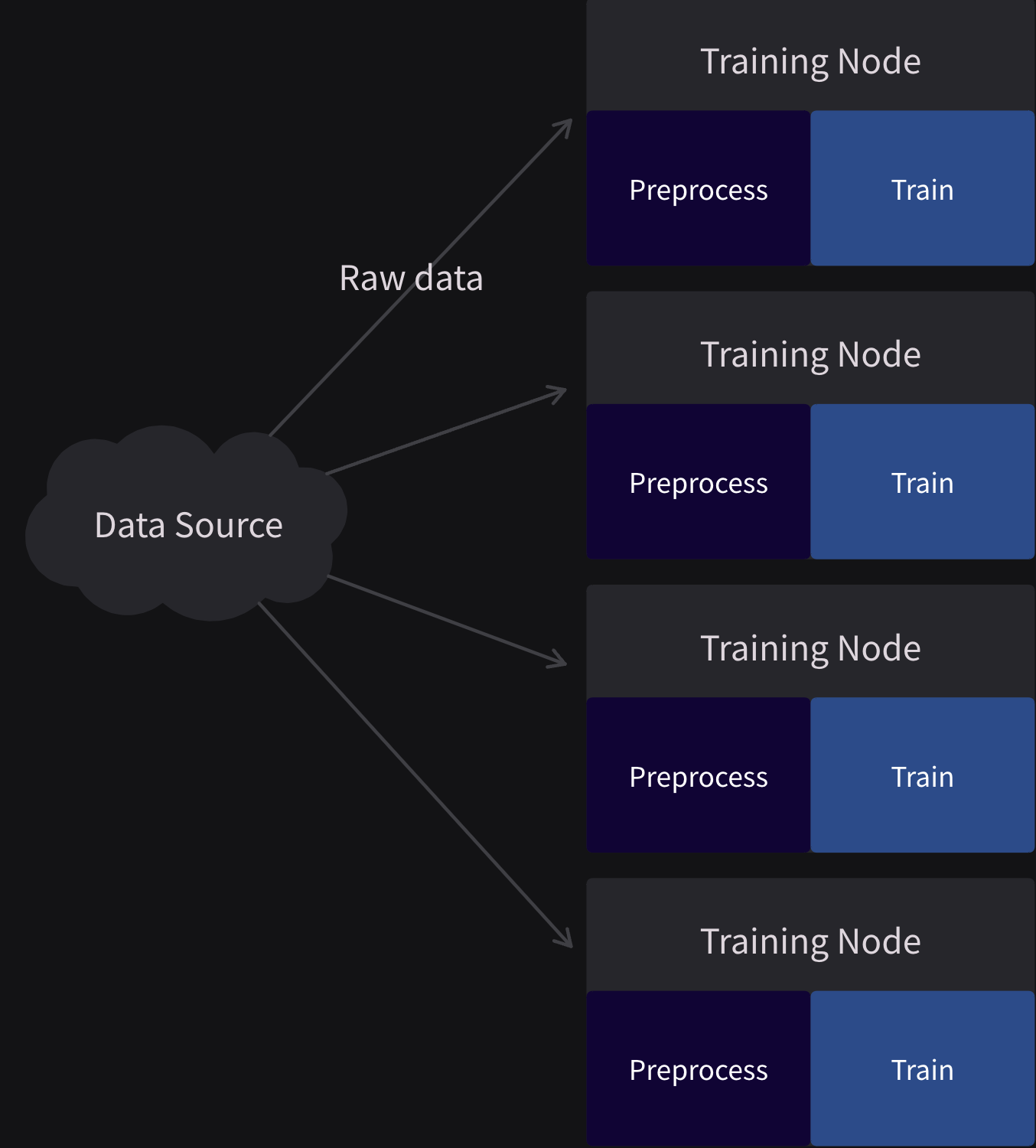
Lavender data introduces a client-server architecture to offload data preprocessing from your training pipeline.
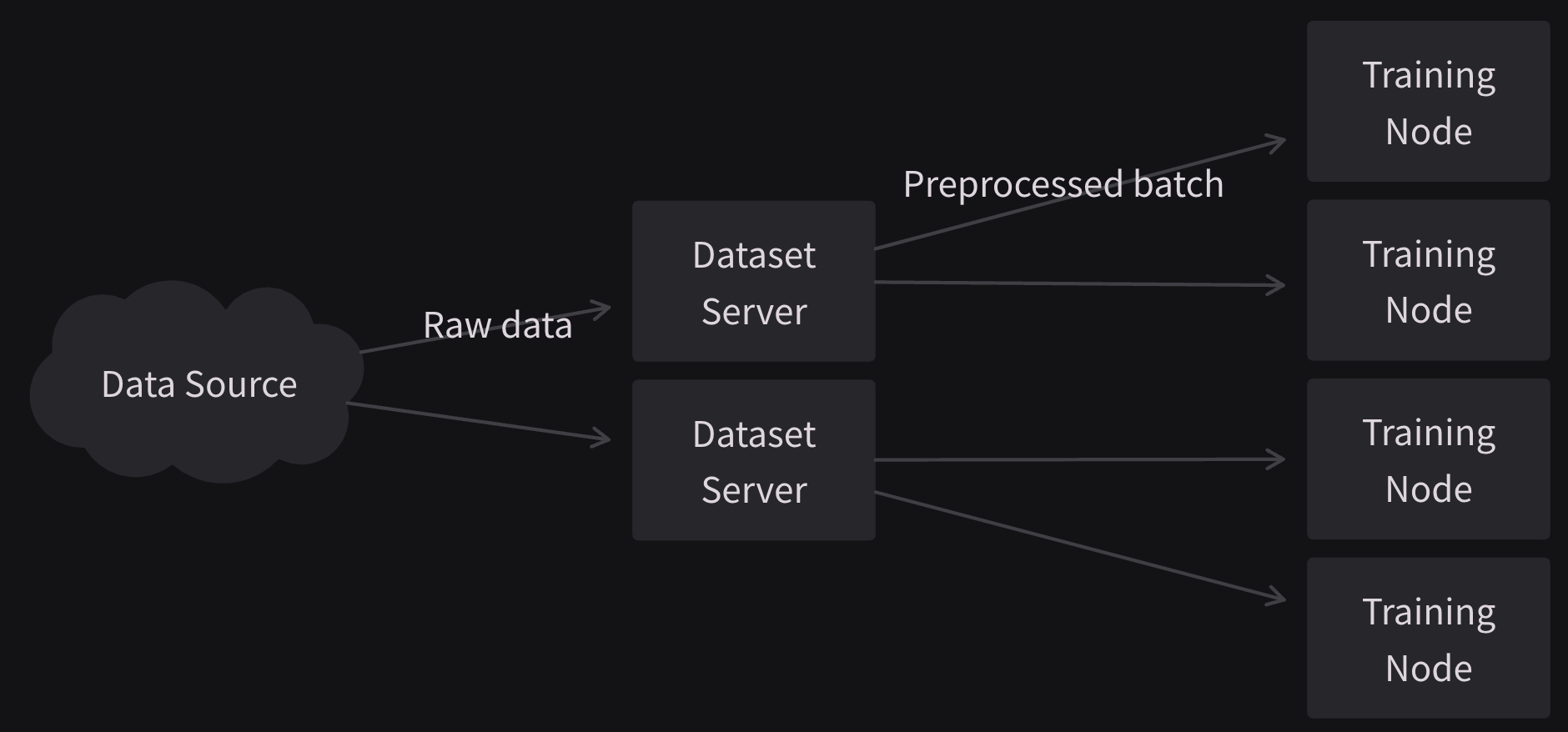
The server is responsible for:
- Manage datasets & shardsets metadata
- Manage iterations, determine which samples to load
- Preprocess and cache data
- Serve preprocessed data to trainer nodes
Shardset
Normally, a dataset is a single file containing all the data, or multiple files (a.k.a. shards) with the same schema.
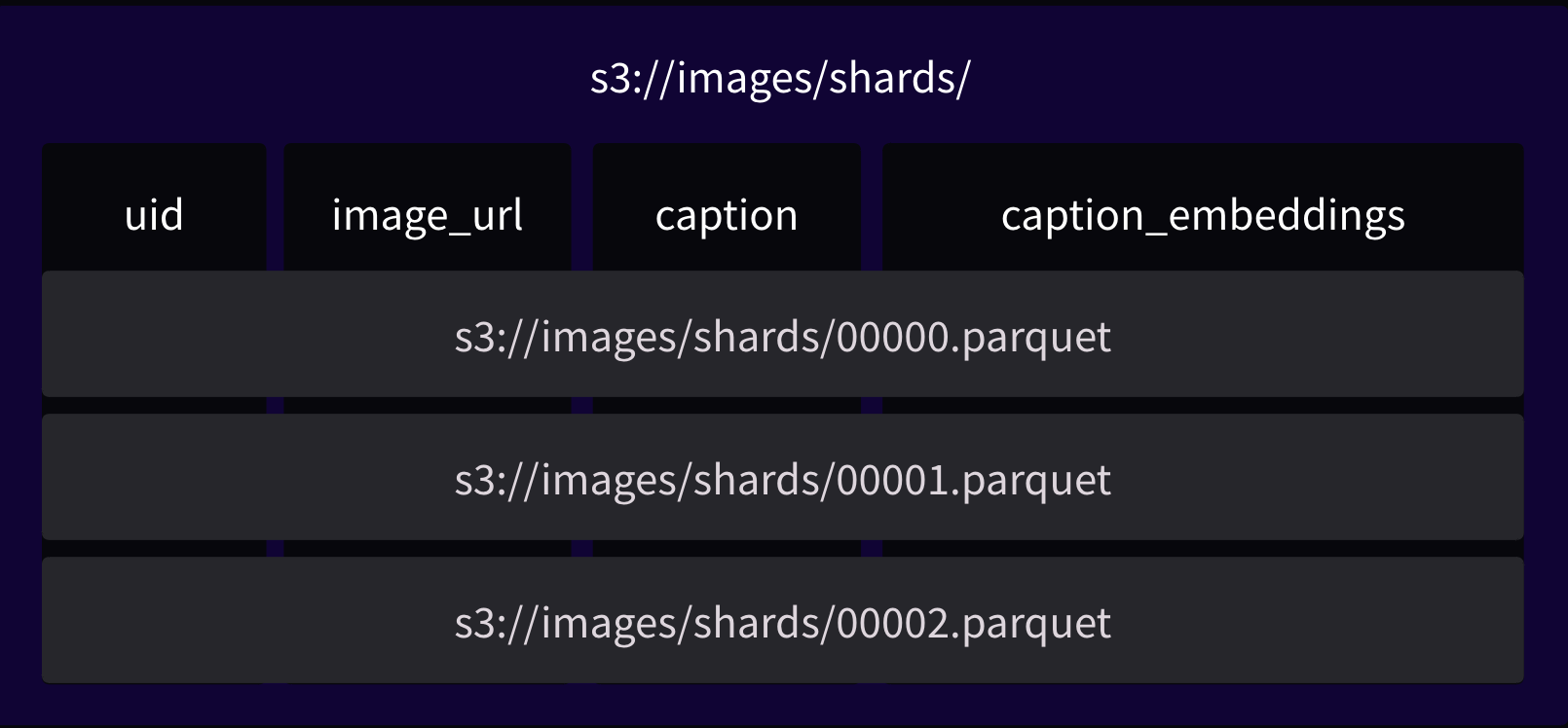
This might be problematic when you want to add a new feature, or you don’t want to load a certain large column.
-
I just want to add this tiny feature
What if you want to add a 10MB column but the parquet files are 100GB?
-
I don’t need that column
What if you don’t need to load
caption_embeddingsand it consumes 99% of the file size?
Lavender data introduces a shardset layer to solve this problem.
A Shardset represents a collection of related columns (features) stored as Shards (files).

-
I just want to add this tiny feature
Add a new shardset!
-
I don’t need that column
Use only desired shardsets during the training!